#라즈베리파이#라즈베리파이 비밀번호#라즈베리 비밀번호 변경#라즈베리 파이 비번#라즈베리 파이 비번 변경#Raspberry Pi#Raspberry Pi password#Raspberry Pi passwd#raspberrypi password#how to change raspberry pi password#how to change password on Raspberry Pi#passwd raspberry pi#linux#Raspbian#Raspbian passwd#raspberry pi root password#raspberry pi root passwd
#자바스크립트#자바스크립트 타입#자바스크립트 undefined#자바스크립트 null#자바스크립트 null undefined 차이#자바스크립트 undefined null 차이#JavaScript#javascript undefined#javascript null#javascript null and undefined#javascript undefined and null#javascript difference between undefined and null#javascript difference between null and undefined#difference between null and undefined#ECMAScript#ES6#ES5#ES2017
컴퓨터에서 다양한 작업을 하다보면 자주 사용하는 기능이나 앱을 키보드 단축키로 설정해놓으면 매우 편리하다. 맥(macOS)에서는 터미널(Terminal), 파인더(Finder), 또는 크롬 브라우저(Google Chrome) 등을 자주 사용하는데, 자주 쓰는 앱을 실행할 때마다 Spotlight Search 또는 Launchpad를 사용하는 것을 매우 번거로운 일이다.
따라서 이번 포스트에서는 맥(macOS)에서 키보드 단축키(Keyboard Shortcuts)를 설정하여 빠르고 편리하게 앱을 열 수 있는 방법에 대해서 알아보도록 하겠다. 이를 위해서 우리는 맥에서 기본적으로 제공하는 오토메이터(Automator) 툴을 사용하도록 할 것이다.
2. 단축키 설정 방법
1) Automator 설정
(1) 메뉴바에서 돋보기 모양의 아이콘을 클릭하거나 또는 단축키 Command + Space를 입력하여 Spotlight Search를 연다. 그리고 "Automator" 또는 "오토메이터"를 입력하여 실행한다(또는 런치패드(Launchpad)를 사용하여 오토메이터(Automator)를 실행한다.)
(2) Automator 앱을 실행하면 다음과 같이 새로운 작업을 만드는 창이 뜨는데 여기서 Quick Action을 선택한다(만약 새로운 작업 생성 창이 나타나지 않을 경우에는 File > New를 선택한다.)
(3) Workflow receives current 항목에서 no input을 선택한다.
(4) 왼쪽에 보이는 Actions 리스트 중에서 Launch Application을 선택하고 오른쪽 방향으로 드래그(drag)하여 워크플로우에 추가한다.
(5) 단축키를 이용해 실행할 어플리케이션을 찾아서 선택한다. 이 예제에서는 터미널(Terminal) 프로그램을 선택하였다.
(3) 왼쪽에 메뉴에 있는 Services를 선택하고, 방금 우리가 추가한 작업을 선택한다.
(4) Add Shortcut 버튼을 클릭하고, 원하는 단축키 조합을 입력하여 설정한다.
3) 단축키 동작 확인
(1) 앞서 설정한 단축키 조합을 입력하여 해당 어플리케이션이 실행되는 것을 확인한다.
Note: 만약 지정한 단축키를 입력해도 앱이 실행되지 않을 경우 바탕화면을 선택한 후, 메뉴바에서 Finder > Services를 한 번 클릭한 후 다시 바탕화면을 선택한 다음, 단축키를 입력하면 앱이 실행될 것이다. 이것은 맥의 키보드 단축키 설정 버그로서 현재 macOS 10.15 Beta 버전을 기준으로 아직까지 버그가 수정되지 않은 것으로 보인다.
#맥북#맥#맥북 단축키#맥 단축키#맥북 터미널 단축키#맥 터미널 단축키#맥북 단축키 설정#macOS#mac shortcut#MacBook terminal keyboard shortcut#macOS shortcut#how to set a keyboard shortcut to open an app#macOS terminal shortcut
Github 계정을 새로 만들었을 경우, 새로 만든 계정으로 스위치해서 git commit, git push 명령을 실행해야 한다. 하지만 기존의 계정 정보(credentials)가 로컬 머신에 저장되어 있기 때문에 git 명령을 실행하면 예전 사용하던 계정으로 이벤트가 기록된다.
그러므로 이전 계정의 정보(credentials)을 삭제하고 새로운 계정을 추가해야 하는데, 단순히 git config --global user.name과 git config --global user.email을 수정하는 것만으로는 계정이 스위치되지 않는다.
macOS에서는 git의 계정 정보(credentials)가 KeyChain 툴에 저장되는데, 따라서 새로운 계정으로 변경하기 위해서는 KeyChain 안에 저장된 계정 정보를 삭제한 뒤, 새로운 계정을 등록해야 한다.
이번 포스트에서는 macOS에서 어떻게 git 계정을 변경하는지 알아보도록 하자.
2. Git 계정 변경 방법
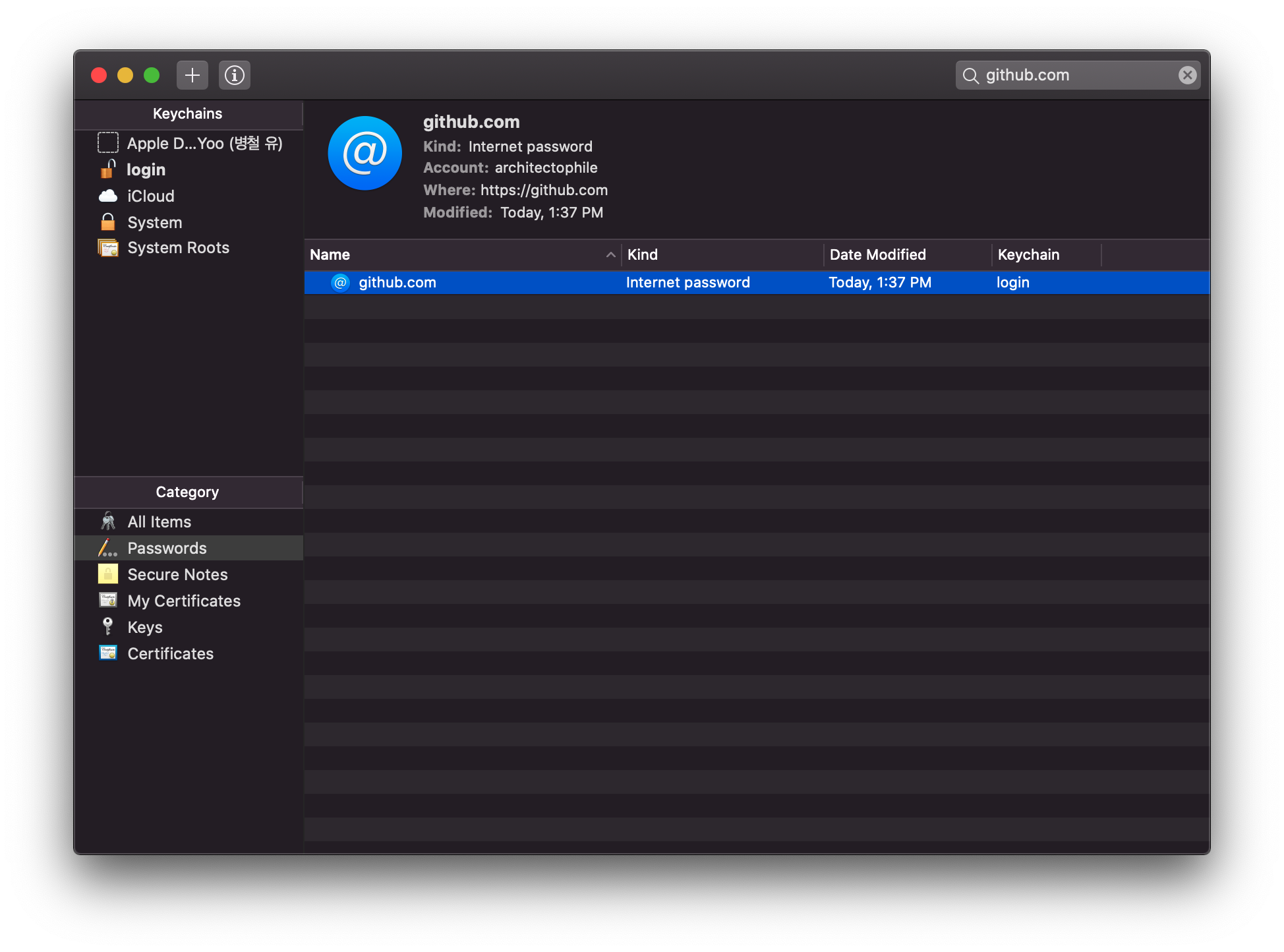
1) KeyChain Access 실행
KeyChain Access 툴을 실행하고 github.com으로 검색을 해보면 다음과 같이 기존에 저장된 계정 정보를 확인할 수 있다.
2) 계정 정보 삭제
다음 명령을 실행하여 기존에 등록된 git 계정의 정보(credentials)를 삭제한다.
Nginx의 가장 강력한 기능 중 하나는 HTML이나 미디어 파일 같은 정적 컨텐츠를 효율적으로 서브하는 것이다. Nginx는 비동기적 이벤트 드리븐 모델(asynchronous event-driven model)을 사용하는데, 이것은 부하(load)에 대해 예측가능한 성능을 제공한다.
Nginx는 동적 컨텐트에 대해서는 CGI, FastCGI, 또는 아파치(Apache)와 같은 다른 서버에게 처리를 맡긴다. 이러한 동적 컨텐츠는 다시 Nginx에게 전달되어 결과적으로 클라이언트에게 전달된다. 이 글은 당신이 Nginx의 파라미터와 컨벤션에 익숙하게 만들어줄 것이다.
1. 디렉티브(Directives), 블록(Blocks), 그리고 컨텍스트(Contexts)
모든 nginx 컨피겨레이션 파일들은 /etc/nginx 디렉토리 안에 위치한다. 가장 주요한 컨피겨레이션 파일은 /etc/nginx/nginx.conf 파일이다.
nginx에서 켠피겨레이션 옵션은 디렉티브(directives)라고 불린다. 디렉티브는 블록(blocks) 또는 컨텍스트(contexts)라고 알려진 그룹으로 구성된다. 이 블록과 컨텍스트는 nginx에서 동일한 의미로 사용된다.
# 문자로 시작하는 줄은 주석으로서 nginx에 의해 해석되지 않는다. 디렉티브를 나타낼 때는 반드시 세미콜론(;)으로 끝나거나, 또는 중괄호 블록({})로 끝나야 한다.
아래에 보이는 것은 nginx 리포지토리에서 설치했을 때 디폴트로 포함되는 /etc/nginx/nginx.conf 파일의 압축된 형태이다. 이 컨피겨레이션 파일은 4개의 디렉티브(directives)로 시작한다: user, worker_processes, error_log, 그리고 pid이다. 이 디렉티브들은 어떠한 특정한 블록이나 컨텍스트 안에 포함되지 않는다. 따라서 그들은 메인 컨텍스트(main context) 안에 있다고 불린다. 그리고 events와 http 블록은 추가적인 디렉티브를 위한 공간이며, 그들 또한 메인 컨텍스트 안에 존재한다.
http 블록은 웹 트래픽을 처리하는 디렉티브들을 담고있다. 이 디렉티브들은 종종 Universal으로 불리는데, 왜냐하면 그것들은 nginx가 서브하는 모든 웹사이트 컨피겨레이션에 전달되기 때문이다. http 블록에서 사용되는 모든 디렉티브들의 목록은 Nginx 문서에서 찾아볼 수 있다.
위의 http 블록 안에 있는 include 디렉티브는 nginx에게 웹사이트 컨피겨레이션 파일이 어디에 위치해 있는지를 알려준다. 만약 nginx 리포지토리에서 설치했다면 위에서와 같이 http 블록 안에 include /etc/nginx/conf.d/*.conf; 디렉티브가 포함되어 있을 것이다. 호스팅하는 각 웹사이트는 반드시 /etc/nginx/conf.d/ 디렉토리 안에 example.com.conf 형태로 만들어진 각자 자신만의 컨피겨레이션 파일을 갖고 있어야 한다. 그리고 사이트 중에서 비활성화된(disabled) 것들은 반드시 example.com.conf.disabled 형태로 파일 이름을 설정해야 한다.
만약 nginx를 Debian 또는 Ubuntu 리포지토리에서 설치했다면, http 블록 안에는 include /etc/nginx/sites-enabled/*; 디렉티브가 포함되어 있을 것이다. 그 .../sites-enabled/ 디렉토리는 /etc/nginx/sites-available/ 디렉토리 안의 컨피겨레이션 파일들을 가리키는 심링크들(symlinks)을 담고 있다.
당신의 nginx 설치 소스에 따라 샘플 컨피겨레이션 파일은 /etc/nginx/conf.d/default.conf 또는 etc/nginx/sites-enabled/default에 위치할 것이다.
그리고 설치 소스와는 상관없이 서버 컨피겨레이션 파일은 다음과 같은 어떤 하나의 기본 server 블록을 갖고 있을 것이다.
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name example.com www.example.com;
root /var/www/example.com;
index index.html;
try_files $uri /index.html;
}
4. 리스닝 포트(Listening Ports)
listen 디렉티브는 nginx에게 HTTP 연결을 위해 필요한 hostname/IP와 TCP 포트(port)를 알려준다. default_server 인자가 의미하는 것은 이 가상의 호스트가 다른 가상의 호스트들의 listen statement와 매치되지 않는 모든 요청에 응답한다는 것이다. 그리고 두 번째 줄의 listen 디렉티브는 IPv6 형식의 요청을 처리한다는 것이고 default_server가 의미하는 것은 앞서 설명한 것과 동일하다.
5. 이름 기반의 가상 호스팅(Name-Based Virtual Hosting)
server_name 디렉티브는 하나의 IP 주소에 대해 여러개의 도메인(domains)을 사용할 수 있게 한다. 서버는 전달받은 요청 헤더(request header)에 기반하여 어떤 도메인을 서브할지 결정한다.
일반적으로 호스트하고자 하는 하나의 도메인 또는 하나의 사이트당 하나의 파일을 생성한다. 다음의 예제들이 있다.
example.com과 www.example.com 두 개 모두의 도메인에 대한 요청을 처리하는 경우에는 다음과 같이 설정한다.
server_name 디렉티브는 또한 와일드카드(*)를 사용할 수 있다. *.example.com과 .example.com는 둘 다 example.com의 모든 서브도메인들(subdomains)에 대한 요청을 처리하도록 한다.
# /etc/nginx/conf.d/example.com.conf
server {
server_name *.example.com; # 또는 .example.com;
. . .
}
example.으로 시작하는 모든 도메인에 대한 요청을 처리하는 경우 다음과 같이 설정한다.
# /etc/nginx/conf.d/example.com.conf
server {
server_name example.*;
. . .
}
nginx는 유효하지 않은 도메인 네임을 server_name에 사용할 수 있도록 한다. nginx는 요청의 HTTP 헤더에 있는 이름을 사용하여 요청에 응답하며, 해당 도메인 네임이 유효한지 아닌지는 상관없다.
도메인 네임이 아닌 호스트네임(non-domain hostname)을 사용하는 것은 서버가 LAN에 있거나 또는 이미 서버에 요청을 보낼 클라이언트들을 알고 있는 경우 유용하다. 예를 들면 이것은 nginx가 듣고있는 IP 주소들로 설정된 /etc/hosts 엔트리를 사용하는 전면 프록시 서버(front-end proxy servers)를 사용할 때 유용하다.
6. location 블록
location 디렉티브는 서버 안의 리소스에 대한 요청을 어떻게 응답해야 할지를 설정한다. server_name 디렉티브가 nginx에게 해당 도메인에 대한 요청을 어떻게 처리해야 하는지 설정하는 것처럼, location 디렉티브는 특정 파일과 특정 디렉토리에 대한 요청을 처리한다. 예를 들면, http://example.com/blog/와 같은 요청에 대한 처리를 설정한다. 다음과 같은 예가 있다.
위의 location 디렉티브들은 리터럴 스트링(literal string)에 대한 매치이며, 호스트 세그멘트(host segment) 이후에 오는 HTTP 요청에서 어떠한 부분이라도 매치된다. 위와 같은 location 디렉티브 설정에서 다음과 같은 몇 가지 요청들에 대한 예를 살펴보자.
요청(Request):http://example.com/
응답(Response):example.com을 위한 server_name 엔트리가 존재한다는 가정하에, 위의 location / 디렉티브가 요청에 대해 어떻게 응답할지를 결정할 것이다.
Note: nginx는 항상 가장 구체적인 매치(the most specific match)에 대해 요청을 처리할 것이다.
요청(Request):http://example.com/planet/blog/ 또는 http://example.com/planet/blog/about/
응답(Response): 이것은 location /planet/blog/ 디렉티브가 요청에 대해 어떻게 응답할지를 결정할 것이다. 비록 location /planet/ 디렉티브도 매치되긴 하지만 가장 구체적인 매치가 요청을 처리한다.
만약 location 디렉티브 뒤에 틸드(~) 문자가 올 경우, nginx는 레귤러 익스프레션(regular expression) 매치를 수행한다. 위의 매치 예제들은 대소문자를 구분(case-sensitive)하기 때문에 위의 예제에서 첫 번째 location 디렉티브에 대해 IndexPage.php는 매치가되지만 indexpage.php는 매치되지 않는다.
위의 예제에서 두 번째 location 디렉티브에 대해 /BlogPlanet/과 /BlogPlanet/index.php는 매치되지만, /BlogPlanet, /blogplanet/, 또는 /blogplanet/index.php는 매치되지 않는다.
만약 레귤러 익스프레션을 대소문자 구분없이(case-insensitive) 매치되도록 하고 싶다면 a tiled and asterisk(~*)를 사용하도록 한다. 위의 예제에서는 특정 파일 확장자로 끝나는 요청들을 어떻게 처리할지를 나타낸다. 첫 번째 location 디렉티브는 .pl, .PL, .cgi, .CGI, .perl, .Perl, .prl, 그리고 .PrL로 끝나는 어떠한 요청에 대해서도 매치될 것이다.
만약 location 디렉티브 뒤에 a caret and tilde(^~)를 붙인다면, nginx는 특정 스트링과 매치가 있으면 더 이상 다른 매치를 찾기위해 진행하지 않고 바로 그 매치되는 디렉티브를 사용한다. 다른 곳에 더욱 구체적으로 매치되는 디렉티브가 있더라도, 해당 요청이 이러한 디렉티브 중에 하나에 매치된다면 곧바로 그 디렉티브가 사용된다.
마지막으로 location 디렉티브 뒤에 an equals sign(=)를 붙인다면, 요청된 경로(path)에 대해서 정확히 일치하는 매치를 찾으면 다른 location 디렉티브에 대한 서치를 마치고 그 정확히 일치하는 디렉티브를 사용한다. 따라서 위의 예제에서는 http://example.com/는 정확히 일치하므로 매치되지만 http://example.com/index.html는 매치되지 않는다. 정확한 매치를 사용하는 것은 요청 처리 시간을 줄이는데 도움이 되는데, 특정 경로의 요청이 자주 발생한다면 매우 유용할 수 있다.
최종 정리된 디렉티브 매칭 처리 순서는 다음과 같다.
정확한 스트링 매치(exact string matches)를 먼저 찾는다. 만야 매치가 발견될 경우 nginx는 더 이상 서치를 멈추고 해당 디렉티브를 사용하여 요청을 처리한다.
그 다음 나머지 리터럴 스트링 매치(literal string matches)를 찾는다. nginx는 만약 ^~를 가진 매치를 발견했을 경우 서치를 중단하고 해당 디렉티를 사용하여 요청을 처리한다. 만약 ^~ 매치가 없을 경우 다음의 리터럴 스트링 매치를 계속 찾으며 가장 구체적인 매치를 저장해놓는다.
그 다음 레귤러 익스프레션(~ 또는 ~*)을 가진 매치를 찾는다. 만약 요청과 매치되는 레귤러 익스프레션을 찾을 경우 서치를 중단하고 해당 디렉티브를 사용하여 요청을 처리한다.
만약 레귤러 익스프레션과 매치되는 디렉티브를 발견하지 못한다면, 현재 저장되어 있는 가장 구체적으로 매치되는 리터럴 스트링 매치(literal string match)가 사용된다.
Note: Nginx에서 location 디렉티브 안에 네스티드 블록(nested blocks)은 지원하지 않는다.
7. location 블록의 root와 index
location 디렉티브는 자체적인 인자값(arguments)을 갖고 있는 블록이다.
nginx가 어떤 location 디렉티브가 요청에 대해 가장 적절한 매치인지 결정하면, 이 요청에 대한 응답은 해당 location 디렉티브 블록 안에 있는 관련된 컨텐츠에 의해 결정된다. 다음과 같은 예제를 살펴보자.
# /etc/nginx/sites-available/example.com
server {
location / {
root html;
index index.html index.htm;
}
}
이 예제에서 해당 location의 문서의 root는 html/ 디렉토리에 있다. nginx의 디폴트 프리픽스에 의해서 전체 경로는 /etc/nginx/html/이다.
응답(Response): nginx는 /etc/nginx/html/blog/includes/style.css에 위치한 파일을 서브할 것이다.
Note: root 디렉티브에는 절대경로(absolute paths) 또한 사용할 수 있다.
index 디렉티브는 아무런 파일명이 명시되어 있지 않을 때 어떤 것을 서브해야 하는지를 알려준다. 다음 예를 보자.
요청(Request):http://example.com
응답(Response): nginx는 /etc/nginx/html/index.html에 있는 파일을 서브할 것이다.
만약 index 디렉티브에 여러개의 파일이 명시되어 있다면, nginx는 파라미터들이 쓰여진 순서대로 처리하며, 그 중에서 파일이 존재하면 응답할 것이다. 즉 위의 예제에서는 index.html 파일을 먼저 찾아보고 없을 경우에는 다음으로 index.htm 파일을 찾아보고 이것도 없을 경우 404 오류(Not Found)를 응답한다.
다음은 도메인 example.com에 대응하는 서버의 조금 더 복잡한 형태의 location 디렉티브들을 보여주고 있다.
# /etc/nginx/sites-available/example.com
server {
location / {
root /srv/www/example.com/public_html;
index index.html index.htm;
}
location ~ \.pl$ {
gzip off;
include /etc/nginx/fastcgi_params;
fastcgi_pass unix:/var/run/fcgiwrap.socket;
fastcgi_index index.pl;
fastcgi_param SCRIPT_FILENAME /srv/www/example.com/public_html$fastcgi_script_name;
}
}
위의 예제에서, 확장자가 .pl로 끝나는 모든 요처들은 두 번재 location 블록에 의해 처리되며, 그것은 fastcgi 핸들러를 명시하여 요청들을 처리한다. 그 외 나머지 요청에 대해서는 nginx는 첫 번째 location 디렉티브를 사용한다. 리소스들은 파일 시스템의 /srv/www/example.com/public_html/ 디렉토리에 위치한다. 만약 요청에서 파일 이름이 명시되지 않을 경우에는 nginx는 index.html 또는 index.htm 파일을 제공할 것이다. 만약 두 개의 파일 모두 존재하지 않을 경우 서버는 404 오류(Not Found)를 응답한다.
몇 가지 요청들에 대해서 위의 예제 서버가 어떻게 응답하는지 살펴보자.
요청(Request):http://example.com/
응답(Response): 우선 /srv/www/example.com/public_html/index.html 파일을 찾아보고 만약 존재하지 않으면 /srv/www/example.com/public_html/index.htm 파일을 찾아볼 것이다. 만약 둘 다 존재하지 않으면 서버는 404 오류(Not Found)를 응답한다.
요청(Request):http://example.com/blog/
응답(Response): 우선 /srv/www/example.com/public_html/blog/index.html 파일을 찾아보고 만약 존재하지 않으면 /srv/www/example.com/public_html/blog/index.htm파일을 찾아볼 것이다. 만약 둘 다 존재하지 않으면 서버는 404 오류(Not Found)를 응답한다.
요청(Request):http://example.com/tasks.pl
응답(Response): nginx는 FastCGI 핸들러를 사용하여 /srv/www/example.com/public_html/tasks.pl에 존재하는 파일을 실행하고 결과를 응답한다.
요청(Request):http://example.com/username/roster.pl
응답(Response): nginx는 FastCGI 핸들러를 사용하여 /srv/www/example.com/public_html/username/roster.pl에 존재하는 파일을 실행하고 결과를 응답한다.
nginx는 1개의 마스터 프로세스(master process)와 여러개의 워커 프로세스들(worker processes)을 가지고 있다. 마스터 프로세스의 주요 역할은 설정(configuration)을 읽고 평가하고, 워커 프로세스들을 관리하는 것이다. 반면 워커 프로세스들의 역할은 실질적인 요청들(requests)을 처리하는 것이다. nginx는 이벤트 기반 모델(event-based model) 사용하며, 운영체제 의존적인(OS-dependent) 메커니즘을 활용하여 워커 프로세스들 사이의 요청을 효율적으로 분배한다. 워커 프로세스의 개수는 컨피겨레이션 파일 안에 정의되어 있는데, 설정에 따라 절대적인 개수로 고정될 수도 있고 또는 가용한 CPU 코어의 개수에 따라 자동으로 조절될 수도 있다.
nginx와 그 모듈들이 동작하는 방식은 컨피겨레이션 파일 안에서 결정된다. 디폴트로는 그 컨피겨레이션 파일 이름은 nginx.conf로 되어 있으며, 그 파일이 위치하는 디렉토리는 /usr/local/nginx/conf, /etc/nginx, 또는 /usr/local/etc/nginx이다.
2. Nginx 시작, 중지 그리고 리로딩 설정 방법
nginx를 시작하기 위해서는 우선 실행파일(executable file)을 실행한다. nginx가 시작되면 실행파일을 -s 파라미터와 함께 실행하여 컨트롤할 수 있다. 사용 문법은 다음과 같다.
nginx -s [signal]
signal의 종류는 다음과 같이 4가지가 있다.
stop : 빠른 종료(fast shutdown)
quit : 우아한 종료(graceful shutdown)
reload : 컨피겨레이션 파일(configuration file) 다시 로딩하기
reopen : 로그 파일 다시 열기
예를 들어, nginx를 종료할 때 워커 프로세스들이 현재 처리하고 있는 요청들을 모두 완료할 때까지 기다리고 싶을 때는 다음과 같은 명령을 사용한다.
foo@bar:~$ nginx -s quit
위 명령은 nginx를 실행시킨 유저와 동일한 유저에 의해 실행되어야 한다. 만약 nginx를 실행한 유저가 root 유저일 경우 권한 획득을 위해 sudo와 같은 명령을 함께 사용해야 한다.
컨피겨레이션 파일이 변경되었을 경우, nginx에 reload 명령을 보내거나 nginx를 재시작하기 전까지는 변경된 설정은 적용되지 않는다. 컨피겨레이션을 리로드하기 위해서는 다음과 같은 명령을 사용한다.
foo@bar:~$ nginx -s reload
마스터 프로세스가 reload 시그널을 전달받은 경우, 그것은 우선 새로운 컨피겨레이션 파일의 문법 유효성 검사를 마친 뒤, 새로운 설정을 적용한다. 만약 문법 검사에서 이상이 없을 경우, 마스터 프로세스는 새로운 워커 프로세스들을 실행시키고, 예전 워커 프로세스들에게는 메시지를 보내 종료 요청을 한다. 예전 워커 프로세스들은 종료 요청을 받으면 더 이상 새로운 요청은 거부하고 기존에 처리하던 요청들을 마무리한 뒤 종료한다.
하지만 만약 문법 검사에 이상이 있거나 오류가 발생했을 경우에는 마스터 프로세스는 변경 내용을 롤백(roll back)하고 이전 설정(configuration)으로 계속 작업한다.
signal은 kill과 같은 Unix 툴을 사용하여 nginx 프로세스에게 전달될 수 있다. 이 경우에는 signal은 프로세스 ID를 이용해 프로세스에게 직접 전달된다. 그 nginx 마스터 프로세스의 프로세스 ID는 기본적으로 /usr/local/nginx/logs 또는 /var/run 디렉토리에 있는 nginx.pid 파일에 쓰여있다. 만약 마스터 프로세스의 프로세스 ID가 1628일 경우, nginx에게 우아한 종료(graceful shutdown) 요청을 보내기 위해서는 다음과 같이 명령을 사용할 수 있다.
foo@bar:~$ kill -s QUIT 1628
실행 중인 모든 nginx 프로세스들의 목록을 얻기 위해서는 ps 유틸리티를 사용하여 다음과 같이 명령을 사용한다.
foo@bar:~$ ps -ax | grep nginx
3. 컨피겨레이션 파일(configuration file) 구조
nginx는 여러 개의 모듈들로 구성되어 있는데, 그것들은 컨피겨레이션 파일 안의 디렉티브(directives)에 의해 제어된다. 디렉티브들은 심플 디렉티브(simple directives)와 블록 디렉티브(block directives)로 나뉜다. 심플 디렉티브의 이름과 파라미터는 스페이스(spaces)에 의해 구분되고 세미콜론(;)으로 끝난다. 블록 디렉티브는 심플 디렉티브와 기본적으로는 동일한 구조를 가지는데, 하지만 세미콜론 대신에 그것은 중괄호(braces)로 둘러싸인 추가적인 명령들의 집합이 뒤에 붙는다. 그리고 만약 블록 디렉티브가 중괄호 안에 다른 디렉티브를 가질 수 있으면 그것은 컨텍스트(context)라고 불린다(e.g. events, http, server 그리고 location 등).
컨피겨레이션 파일 안에서 다른 컨텍스트 밖에 있는 디렉티브들은 모두 메인 컨텍스트(main context) 안에 있는 것으로 본다. events와 http 디렉티브는 메인 컨텍스트 안에 있는 것이고, server 디렉티브는 http 컨텍스트 안에, 그리고 location 디렉티브는 server 컨텍스트 안에 있는 것이다.
그리고 # 기호 이후에 오는 모든 줄은 주석으로 간주된다.
4. 정적 컨텐트(static content) 서빙
웹 서버의 중요한 업무는 파일들(e.g. images 또는 정적 HTML pages 등)을 서빙하는 것이다. 이제 우리는 서버에 들어오는 요청에 따라서 서로 다른 로컬 디렉토리들(/data/www(HTML 파일 디렉토리) 그리고 /data/images(이미지 파일 디렉토리))에 있는 파일들이 서빙되는 예제를 구현할 것이다. 이를 위해서 컨피겨레이션 파일을 수정해야 하는데, http 블록 안에 server 블록을 설정하고, 그 server 블록 안에는 두 개의 location 블록들을 설정할 것이다.
우선, /data/www 디렉토리를 생성하고 그 안에 index.html 파일을 만들고 아무런 텍스트 내요을 작성한다. 그리고 /data/images/ 디렉토리를 만들고 그 안에 몇 장의 이미지 파일들을 넣는다.
그 다음 컨피겨레이션 파일을 연다. 디폴트 컨피겨레이션 파일 안에는 이미 몇 개의 server 블록에 대한 예제들이 포함되어 있는데, 대부분은 주석으로 처리되어있다. 이제 다른 모든 블록들을 주석으로 처리하고 새로운 server 블록을 다음과 같이 작성한다.
http {
server {
}
}
일반적으로 컨피겨레이션 파일 안에는 여러개의 server 블록들을 포함할 수 있는데, 그것들은 사용하는 포트번호 또는 서버이름에 따라 나뉘어져있다. 어떤 요청이 들어오면 nginx는 우선 어떤 server 블록이 해당 요청을 처리할지 결정하고, 그 다음은 요청 헤더(header)에 있는 URI를 server 블록 안의 location 디렉티브들의 파라미터(parameters)와 대조하여 검사한다.
이제 server 블록 안에 다음의 location 블록을 추가한다.
location / {
root /data/www;
}
위의 location 블록은 요청에서 URI와 비교하여 "/" 프리픽스(prefix)를 나타낸다. 매칭되는 요청에 대해서 root 디렉티브에 설정된 경로(path)에 해당 URI가 붙여진다. 즉, /data/www에 붙여져서 로컬 파일 시스템에 있는 요청된 파일에 대한 경로를 형성한다. 만약 location 블록들 중에 매칭되는 것이 여러개 있다면, nginx는 그 중 가장 긴 프리픽스(prefix)를 가진 것을 선택한다. 위의 location 블록은 길이 1의 가장 짧은 프리픽스를 제공한다. 따라서 다른 모든 location 블록들이 매칭에 실패할 경우 이 블록이 사용될 것이다.
이제 아래의 두 번째 location 블록을 추가한다.
location /images/ {
root /data;
}
위의 location 블록은 /images/로 시작하는 요청에 대해 매치가될 것이다(location / 블록에도 역시 매치될 것이지만 이것은 가장 짧은 길이의 프리픽스이다.)
이것은 이미 포트 80에서 듣고 있는 서버로 동작하는 컨피겨레이션이며, 그것은 로컬 머신에서 http://localhost/로 접속이 가능하다. 그리고 /images/로 시작하는 URI를 가진 요청에 대해서는 서버는 /data/images 디렉토리에서 파일을 전송할 것이다. 예를 들어, http://localhost/images/example.png 요청에 대한 응답으로 nginx는 /data/images/example.png 파일을 전송할 것이다. 만약 그 파일이 존재하지 않을 경우 nginx는 404 오류(Not Found)를 전송할 것이다. 그리고 /images/로 시작하지 않는 URI를 가진 요청은 /data/www 디렉토리로 맵핑될 것이다. 예를 들어, http://localhost/some/example.html 요청에 대한 응답으로 nginx는 /data/www/some/example.html 파일을 전송할 것이다.
새로운 컨피겨레이션을 적용하기 위해서, 아직 nginx를 실행하지 않았으면 nginx를 시작시키고, 이미 샐행 중인 경우 다음과 같이 reload 시그널을 마스터 프로세스에 전송한다.
foo@bar:~$ nginx -s reload
Note: 만약 어떤 것이 예상한대로 동작하지 않을 경우, /usr/local/nginx/logs 또는 /var/log/nginx 디렉토리 안에 있는 access.log 또는 error.log 파일을 확인해 볼 수 있다.
5. 간단한 프록시 서버(proxy server) 세팅
nginx의 가장 흔한 사용 중 하나는 그것을 프록시 서버로 사용하는 것이다. 따라서 프로시 서버는 요청을 받으면 프록시된 다른 서버에게 요청을 전달하고, 그들에게 받은 응답을 결과적으로 클라이언트에게 전송한다.
우리는 기본적인 프록시 서버를 하나 설정할 것인데, 그것은 로컬 디렉토리에 있는 이미지 파일에 대한 요청을 처리하고, 나머지 모든 요청들은 프록시된 서버에게 전달한다. 이 예제에서, 두 서버 모두 하나의 nginx 인스턴스에서 정의된다.
우선, 프록시된 서버를 하나 정의할 것인데, 다음과 같이 컨피겨레이션 파일에 하나의 server 블록을 추가한다.
이것은 포트 8080을 듣고 있는 간단한 서버가 될 것인데(이전에는 listen 디렉티브를 생략했었는데, 왜냐하면 표준 포트인 80번이 사용되었기 때문이다.) 이 서버는 모든 요청을 로컬 파일 시스템의 /data/up1 디렉토리로 맵핑할 것이다. 따라서 /data/up1 디렉토리를 생성하고 이 안에 새로운 index.html 파일을 만들어 넣도록한다. 이 때 잘 보아야할 것은 root 디렉티브가 server 컨텍스트 안에 위치한다는 점이다. 그러한 root 디렉티브는 어떤 요청에 대해 선택된 location 블록이 자체적인 root 디렉티브를 갖고 있지 않을 때 사용된다.
다음으로, 이전에 작성했던 server 컨피겨레이션을 수정하여 프록시 컨피겨레이션으로 만들어보자. 첫 번째 location 블록에는 proxy_pass 디렉티브와 함께 프록시된 서버의 프로토콜, 이름, 포트 번호를 파라미터에 명시된대로 넣어준다(이 경우에는 http://localhost:8080가 된다.)
위의 파라미터는 레귤러 익스프레션(regular expression)이며 이것은 .gif, .jpg, 또는 .png로 끝나는 모든 URI와 매치된다. 레귤러 익스프레션은 반드시 ~ 심볼을 앞에 붙여야한다. 이에 해당하는 요청들은 모두 /data/images 디렉토리로 맵핑될 것이다.
nginx가 요청을 처리하기 위해 어떤 location 블록을 선택할 때는, 우선 각 location 디렉티브의 프리픽스(prefix)를 검사하고 매치되는 가장 긴 프리픽스를 가진 하나의 location 블록을 기억해둔다. 그 다음으로 레귤러 익스프레션을 검사한다. 만약 매치되는 레귤러 익스프레션이 있을 경우 그 location을 선택하게 되고, 매치되는 레귤러 익스프레션이 없을 경우에는 이전에 기억해두었던 location 블록을 선택한다.
nginx는 요청들을 다양한 프레임워크와 PHP와 같은 프로그래밍 언어로 빌드된 어플리케이션을 실행하는 FastCGI 서버들로 라우트(route)하기 위해 사용될 수 있다.
FastCGI 서버와 함께 동작하기 위한 가장 기본적인 nginx 컨피겨레이션은 proxy_pass 대신에 fastcgi_pass 디렉티브를 사용하는 것이다. 그리고 FastCGI 서버에 전달되는 파라미터(parameters)를 설정하기 위해서 fastcgi_param 디렉티브를 사용한다. FastCGI 서버가 localhost:9000에서 접속가능하다고 가정해보자. 이전의 프록시 설정을 기본으로 해서 proxy_pass 디렉티브를 fastcgi_pass 디렉티브로 교체하고 파라미터를 localhost:9000로 설정한다. PHP에서는 SCRIPT_FILENAME 파라미터는 스크립트 이름을 결정하기 위해 사용되며, QUERY_PARAMETER는 요청 파라미터를 전달하기 위해 사용된다. 완성된 컨피겨레이션은 다음과 같다.
이번 리눅스 명령 실행 원리 포스트에서 마지막으로 다룰 주제는 바로 리다이렉션(redirection)이다. 앞서 보았던 포스트들을 통해 우리는 이제 디폴트 스트림들(default streams)이 3개의 디폴트 파일 디스크립터(file descriptors)를 사용하여 어떻게 동작하는지 알게 되었다. 디폴트 스트림들은 키보드를 통해 데이터를 입력(input)받고 터미널을 통해 데이터를 출력(output)한다. 우리는 또한 파이프라인 안에서 프로세스들 사이에서 어떻게 데이터가 전달되는지도 보았다.
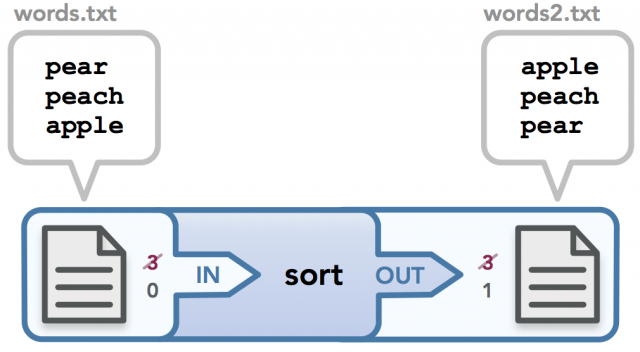
하지만 만약 우리가 파이프라인의 첫 번째 명령에게 입력을 전달할 때 키보드를 사용하지 않고 기존의 파일을 입력으로 전달하고 싶다면 어떻게 해야 할까? 또는 파이프라인의 마지막 명령이 결과를 출력할 때 터미널이 아니라 어떤 파일로 출력하고 싶다면 어떻게 할까? 이런 경우 I/O 리다이렉션(redirection)을 사용할 수 있다. 커맨드 라인(command line)에서 "<" 문자는 입력 리다이렉션(input redirection)을 위해 사용되며, ">" 문자는 출력 리다이렉션(output redirection)을 위해 사용된다. 그리고 출력된 파일은 존재하지 않을 경우 자동으로 생성되며, 만약 이미 존재할 경우에는 기존 파일에 덮어쓰게(overwrite) 된다. 그리고 만약 리다이렉트된 출력 데이터가 파일에 덮어씌워지는(overwritten) 것이 아니라 기존 컨텐츠에 출력 데이터가 추가(append)되는 것을 원할 경우에는 ">>" 문자를 사용할 수 있다. 이제 입력, 출력 리다이렉션을 모두 사용하는 한 예제를 살펴보자. 우리는 다음과 같은 컨텐츠를 담고 있는 words.txt 파일이 있다.
$ cat words.txt
pear
peach
apple
우리는 이 파일을 입력(input)으로 사용하여 sort 명령에 전달한 뒤, 그 결과를 또 다른 파일로 출력(output)할 수 있다(또는 원할 경우 입력과 동일한 파일에 출력할 수도 있다.)
$ < words.txt sort > words2.txt
위의 명령을 입력하면 words.txt 파일이 리다이렉트되어 sort 명령의 입력으로 전달되고, 그 결과는 터미널이 아닌 words2.txt 파일에 출력된다. 우리는 동일한 명령을 다음과 같이 사용할 수도 있다: sort < words.txt > words2.txt cat 명령을 통해 결과를 확인할 수 있다.
$ cat words2.txt
apple
peach
pear
그리고 I/O 리다이렉션을 구현하는 것은 매우 상대적으로 간단하다. 우리는 그저 앞에서 사용했던 dup2() 함수의 마법을 사용하면 된다.
// if first command in pipeline has input redirection
if (hasInputFile && is1stCommand) {
int fdin = open(inputFile, O_RDONLY, 0644);
dup2(fdin, STDIN_FILENO);
close(fdin);
}
// if last command in pipeline has output redirection
if (hasOutputFile && isLastCommand) {
int fdout = open(outputFile, O_WRONLY | O_CREAT | O_TRUNC, 0644);
dup2(fdout, STDOUT_FILENO);
close(fdout);
}
위 코드는 매우 직관적으로 보일 것이라 생각한다. 만약 입력 리다이렉션(input redirection)이 있다면(입력 리다이렉션을 발견하는 함수는 위 코드에서는 생략되어 있다.), 프로세스는 open() 함수를 호출하여 그 입력 파일을 열고(open) 해당 데이터 스트림(data stream)을 open() 함수가 사용하는 파일 디스크립터(file descriptor)에게 할당한다. 그런 다음, 이전 포스트에서처럼 dup2() 함수를 사용하여 해당 파일 디스크립터를 stdin과 연결시킨다. 이와 비슷하게 만약 파이프라인의 마지막 명령에서 출력 리다이렉션(input redirection)이 있을 경우, dup2() 함수를 사용하여 해당 파일 디스크립터를 stdout과 연결시킨다.
아래에 이를 나타내는 다이어그램이 있다.
당신은 아마도 왜 파일 디스크립터들이 입력과 출력에서 모두 3으로 시작하는지 궁금할 것이다. 위의 코드를 살펴보면, 우선 입력 리다이렉션이 있는지 검사한 후에 만약에 있을 경우, 프로세스는 open() 함수를 호출하여 파일을 열고 해당 데이터 스트림을 파일 디스크립터 3에게 할당(assign)한다. 그리고 dup2() 함수를 호출하여 파일 디스크립터 3이 처리하는 데이터를 stdin이 처리하도록 리다이렉트한다. 그 다음 더 이상 필요없는 파일 디스크립터 3을 닫고(close) 나면, 이제 파일 디스크립터 3은 출력 리다이렉션을 처리하기 위해 사용가능한(available) 상태로 다시 바뀌게 된다. 따라서 입력과 출력 파일에 대해 모두 파일 디스크립터 3을 사용한 다음, 적절하게 데이터를 처리하기 위한 스트림들(stdin과 stdout)에게 리다이렉트되고 나면, 더 이상 필요없는 파일 디스크립터 3을 닫는다(close).
이것을 통해 우리는 Unix의 강력한 힘을 엿볼 수 있다. 우리는 파이프를 이용하여 작은 프로그램들을 연결(chain)하여 더 큰 프로그램을 만들 수 있을 뿐만 아니라, I/O 리다이렉션을 이용해 파일로 된 데이터를 파이프라인으로 입력하고, 또한 처리된 결과 데이터를 파일로 출력하여 저장할 수 있는 것이다.
2. 최종 정리
우리가 이번 리눅스 명령 실행 원리 시리즈 3편의 포스트를 통해 배운 것을 정리하기 위해서 마지막으로 아래의 예제와 다이어그램을 살펴보도록 하자.
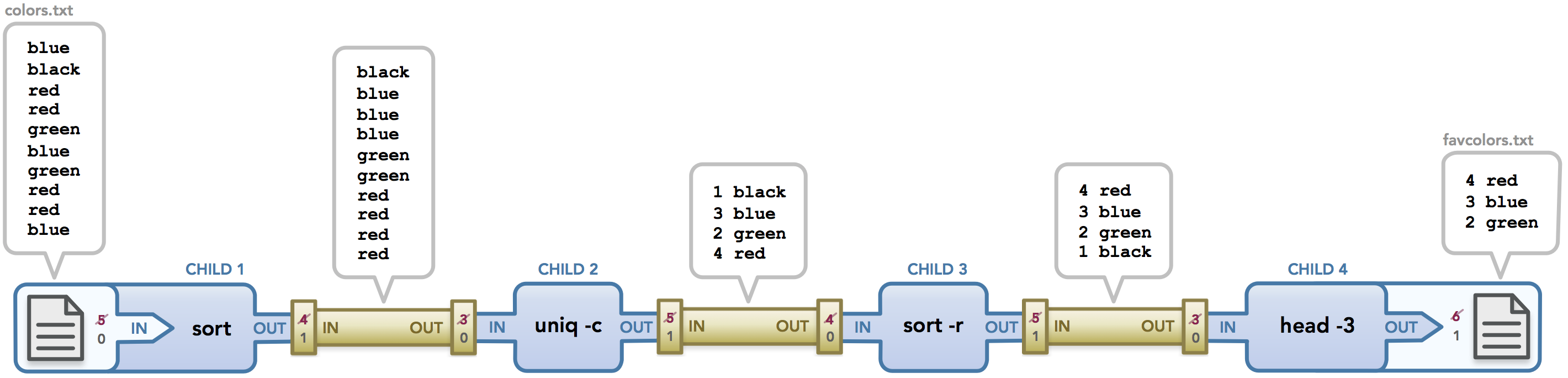
당신은 어떤 그룹의 사람들을 대상으로 그들이 가장 좋아하는 색깔이 무엇인지를 알아보고자 한다고 가정해보자. 우선 당신은 사람들이 가장 좋아하는 색깔이 무엇인지를 조사하여 파일에 적어 저장한다. 따라서 파일의 한 줄마다 사람들이 좋아하는 색깔이 하나씩 적혀있다. 이제 당신은 그 파일에 대해 여러 명령들을 실행하여 최종적으로 가장 인기있는 3개의 색깔이 무엇인지 찾아내고 각 색깔마다 몇명의 투표를 받았는지에 대한 결과를 하나의 파일로 출력하고자 한다. 그리고 이 모든 명령들은 단 하나의 파이프라인(pipeline)에서 처리하고자 한다.
위의 명령은 다음과 같이 처리된다: 우선 colors.txt 파일은 사람들이 좋아하는 색깔들이 무작위 순서로 저장되어 있다. uniq 명령은 이전 라인과 동일한 중복되는 모든 라인을 삭제한다. 그리고 위해서 우선 sort 명령을 사용해 동일한 색깔들이 연속으로 나타나도록 만든다. 그리고 uniq -c를 호출하는데, 이 때 -c 옵션은 중복되는 라인을 삭제한 다음 결과를 출력할 때 왼쪽에 각 중복된 라인의 숫자(count)를 함께 출력한다. 그 다음 우리는 다시 그 처리된 결과에 대해 내림차순(descending order)으로 정렬하기 위해 sort -r 명령을 사용한다. 그리고 마지막으로 head -3 명령을 실행하여 가장 위에 있는 3줄만 출력하는데 이 때 리다이렉션을 통해 favcolors.txt 파일에 출력하여 저장한다. 결과적으로 favcolors.txt 파일에는 다음과 같은 데이터가 저장된다.
$ cat favcolors.txt
4 red
3 blue
2 green
위 예제는 지금까지 다루었던 예제들 보다 더욱 복잡하다. 그리고 위 다이어그램의 파일 디스크립터들 역시 매우 복잡하다. 나의 쉘 프로그램은 I/O 리다이렉션을 검사하기 전에 pipe() 함수를 먼저 호출한다. 따라서 첫 번째 파이프가 파일 디스크립터 3, 4를 사용하게 된다. 그리고 입력과 출력을 위한 파일 디스크립터는 각각 5, 6이 할당된다. 그리고 파일 디스크립터 5, 6이 각각 stdin과 stdout으로 리다이렉트된 이후에는 닫히게(close) 되고, 위의 다이어그램의 양쪽 끝을 보면 이를 알 수 있다. 두 번째 파이프가 생성될 때, 이것은 재활용된 파일 디스크립터를 사용할 수 있는데, 그 이후에 다른 모든 파이프에 대해서도 마찬가지이다. 하지만 파일 디스크립터들이 어떻게 재활용되는지에 대해 너무 집중할 필요는 없다. 그것은 나의 쉘 프로그램과 예제 코드에 따라 결정되는 것이기 때문이다.
유닉스(Unix)는 단순하지만 매우 가치있는 디자인 철학을 갖고 있는데, 유닉스 파이프(Pipe)의 창시자인 Doug McIlroy는 다음과 같이 말했다.
“한 가지 일만 아주 잘하는 프로그램들을 작성하라. 프로그램들이 다른 프로그램들과 함께 일할 수 있도록 작성하라. 프로그램들이 텍스트 스트림을 처리할 수 있도록 작성하라. 왜냐하면 그것은 보편적인 인터페이스이기 때문이다.”
원문 : “Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.”
파이프의 개념은 매우 강력하다. 파이프는 데이터가 한 프로세스에서 다른 프로세스로 전달되도록 하는데(일방향(unidirectional)의 데이터 흐름을 통해서), 그로인해 프로세스들의 명령들이 스트림에 의해 서로 연결된다(chained). 이것은 여러 명령들이 함께 동작하여 더 큰 목적을 달성할 수 있도록 해준다. 이러한 프로세스들의 체이닝(chaining)은 파이프라인(pipeline)으로 표현될 수 있다: 한 파이프라인 안에 있는 명령들(commands)은 서로 파이프(pipes)에 의해서 연결되며, 파이프의 한 쪽 끝에서 다른 쪽 끝으로 데이터가 흐르면서 두 프로세스 사이에 데이터가 공유된다. 이 때 파이프라인 안에 있는 각 명령들은 각자 독립적인 프로세스 안에서 실행되며, 각자 독립적인 메모리 공간에서 실행된다. 그러므로 우리는 각 프로세스들이 서로 통신할 수 있는 방법이 필요하게 되는데, 바로 pipe() 시스템 호출이 그 방법을 제공하는 것이다.
구현에 있어서, 사실 파이프는 그저 버퍼된 스트림(buffered stream)에 불과하며, 그 스트림은 2개의 파일 디스크립터(file descriptors)와 연결되어 있는데, 첫 번째는 데이터를 읽기 위한 것이고, 두 번째는 데이터에 쓰기 위한 것이다. 더욱 구체적으로, 파이프라인의 명령의 실행을 처리하는 코드를 살펴보면, 2개의 정수값을 저장하는 배열(array)이 생성되고, pipe() 호출은 그 배열에 사용 가능한 2개의 파일 디스크립터 값을(일반적으로 사용가능한 가장 낮은 숫자의 2개의 파일 디스크립터를 사용한다.) 채운다(populate).
실제 물리적인 파이프는 지금 설명하는 유닉스 파이프의 추상적인 개념을 설명하는데 매우 좋은 비유이다. 우리는 한 프로세스에서 시작되는 데이터 스트림을 독립된 공간에 들어있는 물이라고 생각할 수 있다. 그리고 그 물이 다음 프로세스의 공간으로 흐를 수 있는 유일한 방법은 각 공간을 파이프(pipe)로 연결하는 것이다. 이러한 방식으로, 그 물(데이터)은 첫 번째 공간(프로세스)에서 파이프로 흘러들어가고, 파이프 안에 물이 가득차면, 다시 그 파이프에서 다음 공간(프로세스)으로 물(데이터)을 흘려보낸다. 아래의 다이어그램은 이러한 데이터 흐름(data flow)을 표현한 예이다(sort | grep ea).
이제 위의 예제를 하나씩 파헤쳐보도록 하자. 기본적으로 sort 명령은 사용자가 stdin(file descriptor 0)을 통해서 입력(input)을 전달할 때까지 기다린다. 그 다음, 입력받은 스트링들은 알파벳 순서대로 정렬되고, 그 정렬된 결과가 stdout을 통해서 파이프(pipe)로 전달된다. 이것은 stdout으로 하여금 출력된 데이터를 터미널 디스플레이(file descriptor 1)가 아니라 파이프의 왼쪽 끝(file descriptor 4)으로 입력(feed)하도록 만듦으로써 가능해진다.
위 예제에서 프로세스의 실행 과정에 대한 더욱 자세한 내용은 추후에 다시 설명하도록 하겠다.
계속 진행하기 전에, 다시 한 번 떠올려야 할 중요한 점이 있는데, 바로 각 프로세스는 자신 만의 파일 디스크립터 테이블(own file descriptor table)을 갖는다는 것이다. 파이프라인의 각 명령은 각자 독립적인 프로세스 안에서 실행되기 때문에, 각 명령은 자신만의 버전의 파일 디스크립터를 갖고 있으며, 자신만의 stdin, stdout, 그리고 stderr를 갖고 있다. 이것이 의미하는 것은 위의 다이어그램에서 왼쪽 끝에 있는 0은 sort 명령을 실행하는 프로세스에 속하는 것이고, 따라서 이것은 다이어그램의 오른쪽 끝에 있는 1과는 다른 파일 디스크립터 테이블 안에 있는 것이고, 그것은 grep 명령을 실행하는 프로세스에 속하는 것이다. 하지만 스트림들은 프로세스 바운더리(process boundaries)를 건너 데이터를 전송하도록 설정되어있기 때문에, 데이터가 파이프라인을 타고 잘 전달된다면 결과적으로 데이터는 마지막 프로세스로 전달될 것이다.
다시 처음부터 살펴보면, sort 명령은 정렬된 스트링 리스트를 출력(output)으로 갖게되고, 그 출력 데이터를 결과적으로 다음 프로세스(grep)에게 전달하기 위해서, 생성된 파이프(pipe)에게 출력 데이터를 전달해야 한다. 우선 잠시 동안은 파일 디스크립터 3, 4에 대해서는 잊도록 하고, 다어이그램에 쓰여 있는 'in'과 'out' 단어들을 살펴보자. 데이터는 sort 프로세스로부터(out of) 파이프로(into) 전달되고, 그것은 다시 파이프로부터(out of) grep 프로세스로(into) 전달된다.
이제 pipe() 호출에 의해 전달되는 파일 디스크립터에 대해서 알아보도록 하자. 파이프라인에서 명령들을 실행하는 코드 안에서, pipe() 호출은 파일 디스크립터 배열 {3, 4}를 채우게(populate) 되고, 따라서 파일 디스크립터 4에 쓰여진(written) 데이터가 파일 디스크립터 3으로부터 읽히도록(read) 만든다. 사실 이 번호들이 숫자가 무엇인지는 별로 중요하지 않다. 배열 속에 들어가는 값들은 오직 프로세스에게만 중요하다. 하지만 각 파일 디스크립터의 용도(purpose)는 데이터에게 있어 매우 중요하다. 그리고 각 파일 디스크립터의 용도는 배열(array) 안에서 몇 번째 인덱스(index)에 위치하느냐에 따라서 결정된다.
그리고 여기에서 알아야 할 매우 중요한 개념이 있는데, 나는 이것을 이해하기 위해 위의 다이어그램들을 그려보며 생각해야 했다. 내가 처음에 얘기했던 것처럼 위의 다이어그램들은 데이터가 왼쪽에서 오른쪽으로 흐르는 모델이라는 것을 잘 생각해보자. 파일 디스크립터는 배열 안에서 설정되어 4에 쓰여진 데이터가 3에서 읽히도록 된다. 하지만 당신은 왜 4가 왼쪽으로 가고 3이 오른쪽으로 가는지 궁금해할 수 있다. 여기서 핵심적인 내용은 바로 pipe() 호출에 의해 설정되는 읽기(read), 쓰기(write) 액션은 바로 파이프를 사용하는 양쪽의 2개의 프로세스들의 관점에서 정의된다는 것이다. 따라서 pipe() 호출에 4를 writable end로 설정하면, 그것은 첫 번째 명령(sort)의 프로세스가 출력(output)을 쓰기(write)하는 파이프의 입력(input)을 전달받는 파이프의 왼쪽 파일 디스크립터가 되는 것이다. 반대로 pipe() 호출에 3을 readable end로 설정하면, 그것은 두 번째 명령(grep)의 프로세스가 입력(input)을 읽기(read)하는 파이프의 출력(output)을 전달하는 파이프의 오른쪽 파일 디스크립터가 되는 것이다.
따라서 데이터는 첫 번째 프로세스(sort)에서 파이프로 전달되고, 파이프는 모든 데이터가 전달될 때까지 기다렸다가 모든 데이터가 전달되면, 파이프는 그 다음 프로세스(grep)로 그 데이터를 내보낸다. 그리고 마지막으로 파이프로부터 데이터를 전달받은 grep 명령을 실행하는 프로세스는 그 입력 데이터 중에서 "ea"가 포함된 라인을 stdout으로 출력하여 터미널로 내보내게 된다.
다음으로 우리는 이러한 프로세스들을 처리하는 코드들에 대해서 더욱 자세히 알아보도록 할 것이다. 지금까지 알아본 pipe() 호출을 이해했다면 우리는 전체 중에서 절반 정도 왔다고 할 수 있다. 나머지 절반은 바로 fork()와 dup2()를 이해하는 것이다. 이제 이 함수들이 어떻게 동작하는지 알아보도록 하자!
2. 파이프라인(pipeline)에서 여러 명령들 실행하기
우리는 지금까지 파이프(pipes)를 이용하여 어떻게 한 프로세스의 데이터가 다른 프로세스로 전달되는지를 살펴보았다. 하지만 우리는 아직 그 명령들을 실행하는 프로세스들의 계층(hierarchy)에 대해서는 아직 다루지 않았다. 수업시간에 우리는 모든 명령들이 자식 프로세스(child process)에서 실행되도록 하거나 또는 부모 프로세스(parent process(calling process))에서 실행되도록 하는 것을 배웠다. 일반적으로 부모 프로세스는 기본적으로 필요한 설정(setup) 작업을 하고, fork() 호출을 통해 자식 프로세스를 생성하여 부모 프로세스의 메모리 상태(memory state)와 파일 디스크립터(file descriptors)를 복제하도록 한다. 따라서 자식 프로세스는 fork() 호출이 실행될 때의 부모 프로세스에 존재했던 동일한 변수(variables)와 파일 디스크립터(file descriptors)를 갖는 독립적인 복사본을 갖게 된다. 그리고 fork() 호출이 끝난 이후에는 자식 프로세스는 더 이상 부모 프로세스의 변화에 대해서 알지 못하고, 반대로 부모 프로세스 역시 자식 프로세스의 변화에 대해서 알지 못한다.
이러한 자식 프로세스 명령 실행 패턴(the children-execute commands pattern)은 그저 싱글 명령(single command)을 처리하는 경우에는 불필요해 보인다. 왜냐하면 굳이 자식 프로세스를 생성하지 않고도 부모 프로세스에서 그 명령을 실행하면 되기 때문이다. 하지만 싱글 명령(single command)이나 또는 파이프라인에서 멀티플 명령들(multiple commands) 모두를 처리할 수 있는 제네릭(generic) 코드를 작성한다고 생각한다면, 이 경우에는 항상 다른 자식 프로세스가 각각 다른 명령을 수행하도록 하는 것이 당연할 것이다. 물론 이 규칙이 적용되지 않는 예외적인 경우도 있지만, 여기서 우리는 모든 명령들이 각기 다른 자식 프로세스에서 실행된다고 가정할 것이다.
이제 다음과 같은 sort 명령을 실행하는 C 코드 예제를 살펴보도록 하자. 이 예제에서 입력(input)은 dprintf() 함수를 사용하여 직접적으로 파일 디스크립터(file descriptor)로 출력되는데, 이것은 파이프를 사용하여 부모 프로세스로부터 자식 프로세스로 데이터가 전달되는 경우를 보여주기 위함이다.
다음의 예제는 우리 수업에서 제공된 샘플 코드를 간략화한 버전이다.
#include <unistd.h>
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
int fds[2]; // an array that will hold two file descriptors
pipe(fds); // populates fds with two file descriptors
pid_t pid = fork(); // create child process that is a clone of the parent
if (pid == 0) { // if pid == 0, then this is the child process
dup2(fds[0], STDIN_FILENO); // fds[0] (the read end of pipe) donates its data to file descriptor 0
close(fds[0]); // file descriptor no longer needed in child since stdin is a copy
close(fds[1]); // file descriptor unused in child
char *argv[] = {(char *)"sort", NULL}; // create argument vector
if (execvp(argv[0], argv) < 0) exit(0); // run sort command (exit if something went wrong)
}
// if we reach here, we are in parent process
close(fds[0]); // file descriptor unused in parent
const char *words[] = {"pear", "peach", "apple"};
// write input to the writable file descriptor so it can be read in from child:
size_t numwords = sizeof(words)/sizeof(words[0]);
for (size_t i = 0; i < numwords; i++) {
dprintf(fds[1], "%s\n", words[i]);
}
// send EOF so child can continue (child blocks until all input has been processed):
close(fds[1]);
int status;
pid_t wpid = waitpid(pid, &status, 0); // wait for child to finish before exiting
return wpid == pid && WIFEXITED(status) ? WEXITSTATUS(status) : -1;
}
이 프로그램은 한 가지 구체적인 명령(sort)을 실행하도록 쓰여졌다. 코드가 동작하는 과정은 다음과 같다.
우선 부모 프로세스(parent process)에서 2개의 파일 디스크립터(file descriptors)를 저장하기 위한 배열(array)이 한 개 생성된다.
pipe() 호출 이후에 그 배열은 연결된 2개의 파일 디스크립터로 채워지게(populate) 된다. 이 때 배열의 첫 번째 요소는자식 프로세스에서 입력(input)을 읽는데(read) 사용되고, 두 번째 요소는부모 프로세스로부터 출력(output)을 쓰는데(write) 사용된다.
fork() 함수가 호출되어 자식 프로세스가 생성되고, 그것은 부모 프로세스의 파일 디스크립터(file descriptors)와 메모리(memory)를 복제한다.
이제 현재 실행 중인 프로세스 아이디(process id)가 자식 프로세스인지(pid == 0) 검사한다.
(1) 자식 프로세스(child process)인 경우
dup2() 함수를 호출하여 자신의 stdin을 파이프(pipe)의 읽기 엔드(read end)와 연결시킨다. 그리고 이것은 fds[0]에 해당한다. 이 때 알아야 할 점은 dup2() 함수가 동작할 때, 두 번째 파라미터의 파일 디스크립터를 먼저 닫는다는(close) 것이다. 따라서 위 예제에서는 stdin(디폴트로 열려 있는 표준 입력)이 먼저 닫히면서, 디폴트 키보드 파일에 대한 레퍼런스가 삭제된다. 그 이후에는 해당 자식 프로세스의 stdin은 더 이상 키보드가 아니라 fds[0]에서 데이터를 입력받게 된다. 이것이 바로 dup2() 함수에서 일어나는 마법이다.
이제 자식 프로세스의 stdin은 데이터를 읽어들일 준비가 되었으며, pipe() 호출에 의해 생성된 파일 디스크립터는 이제 더 이상 필요 없으므로 파일 디스크립터를 닫는다(close): close(fds[0]);close(fds[1]);
이제 자식 프로세스는 execvp() 함수를 호출하여 sort 명령을 실행하고, 부모 프로세스의 모든 데이터가 파이프의 읽기 엔드(readable end)로 쓰여질 때가지 대기한다.
부모 프로세스로부터 모든 데이터가 파이프의 입력 엔드를 통해 자식 프로세스로 전달되면 sort 명령을 통해 데이터를 정렬하고, 그 결과를 stdout을 통해 터미널 디스플레이로 출력한 다음, execvp() 호출이 리턴된 이후, 자식 프로세는 디폴트 파일 디스크립터 0, 1, 그리고 2를 자동으로 닫는다.
(2) 부모 프로세스(parent process)인 경우
부모 프로세스는 fork() 함수를 호출한 이후에 파일 디스크립터 fds[0]를 닫는데, 왜냐하면 부모 프로세스는 데이터를 읽기(read)는 사용하지 않고 데이터를 쓰기(write)만 사용하기 때문이다.
dprintf() 함수를 이용해서 자식 프로세스에게 전달하고자 하는 배열(array) 안에 담긴 단어들(words)을 파이프의 쓰기 엔드(writable end)인 fds[1]에 쓴다. 이 때 각 단어 끝에는 줄바꿈 문자(a new line character('\n'))를 붙여 sort 명령이 한 줄당 한 단어씩 받을 수 있도록 한다.
모든 단어들을 전송한 후에 fds[1]을 닫는다: close(fds[1]);. 이 때 자동으로 EOF(end-of-file)이 전송되고, 그 뒤에 자식 프로세스는 sort 명령을 수행한다.
waitpid() 함수를 호출하여 자식 프로세스가 종료될 때가지 기다린다.
자식 프로세스가 종료되고 나면 부모 프로세스도 종료된다.
아래는 위의 모든 과정에 대한 데이터 흐름 다이어그램이다.
위 예제 코드의 최종 데이터 흐름(data flow)이다. 파일 디스크립터 3은 자식 프로세스에서 stdin으로 복사된 뒤에 종료되었다. 그리고 오직 자식 프로세스의 stdin만 데이터를 읽기 위해 사용되었다.
이 예제는 파이프가 어떻게 동작하는지를 보여주기 위한 것이라는 점을 명심하길 바란다. 사실 위 예제에서 파이프가 꼭 필요한 것은 아니다. 왜냐하면 자식 프로세스는 부모 프로세스의 도움 없이 파이프를 사용하지 않고 그저 디폴트 stdin을 이용해 데이터에 접근할 수도 있다. 하지만 위 예제의 목적은 파이프를 이용해 한 프로세스에서 다른 프로세스로 데이터를 전달하는 것을 보여주기 위함이다. 그리고 이것은 파이프라인에서 1개 이상의 명령들을 처리할 때 매우 중요한 패턴이다.
위 예제 코드에서 어떤 일들이 일어나는지 알아보기 위해 다음의 다이어그램들을 살펴보자. 아래 그림들에서 선(lines)은 파일 디스크립터와 그것이 가진 포인터가 가리키는 오픈 파일 사이의 관계를 나타낸다. 그리고 이 때 화살표의 방향은 데이터 흐름의 방향을 나타낸다. 이러한 다이어그램은 부모와 자식 프로세스에게 어떤 파일 디스크립터가 필요한지를 분명하게 보여주고, 또한 메모리 누수(leak)를 막기 위해 언제 파일 디스크립터를 닫는 것이 적절한지를 알 수 있게 한다. 또한 명심해야 할 점은 부모 프로세스에서 실행되는 명령어들(instructions)이 자식 프로세스의 명령어들(instructions)보다 이전에 실행된다는 보장이 없기 때문에 아래의 몇몇 과정들은 서로 다른 시간에 발생할 수 있다. 아래의 다이어그램들은 명령 실행 과정에서 어떤 일들이 일어나는지에 대한 개념을 제공하기 위한 것이며, 몇몇 과정은 실행 중에 순서가 뒤바뀔 수도 있다.
프로그램이 시작될 때, 부모 프로세스가 생성되고 디폴트 스트림들(default streams)이 그것의 파일 디스크립터 테이블(file descriptor table) 안에 설정된다. 화살표의 방향은 데이터의 흐름 방향을 나타낸다: stdin은 키보드로부터 입력(input)을 받고, stdout과 stderr는 출력(output)을 터미널로 전송한다.
pipe() 함수 호출은 다음으로 사용가능한 파일 디스크립터 2개를 찾고 그것들을 생성된 파이프(pipe)의 읽기 엔드(readable end)와 쓰기 엔드(writable end)와 각각 연결시킨다. 이 다이어그램에서는 프로세스는 3을 통해 읽고, 4를 통해 쓸 수 있다.
fork() 함수 호출은 자식 프로세스를 생성하는데, 그것은 함수 호출 당시의 부모 프로세스의 메모리와 파일 디스크립터 테이블을 복사한다. 이 때 부모 프로세스의 파일 디스크립터가 연결된 파일들(files)이 무엇이든지 간에 자식 프로세스의 파일 디스크립터 역시 동일한 그 파일들(files)과 연결된다.
부모 프로세스는 파이프의 읽기 엔드가 필요없기 때문에 fds[0]을 닫는다(close). 자식 프로세스는 dup2() 함수를 호출하여 디폴트로 stdin과 연결되어 있던 파일 디스크립터 0을 먼저 닫은 후에,fds[0]을 복사하여 stdin에 연결시킨다.
부모 프로세스는 파이프의 쓰기 엔드(writable end)에 데이터를 쓴다. 자식 프로세스는 더 이상 필요없는 파이프의 파일 디스크립터(fds[0]과 fds[1])를 닫는다(close).
부모 프로세스는 모든 데이터를 다 쓰고난 뒤에 fds[1]을 닫는다(close). 그러면 자동으로 EOF가 전송되고 자식 프로세스에게 모든 데이터가 전송되었음을 알리게 된다.
자식 프로세스는 받은 입력(input)에 대해서 sort 명령을 수행한다.
자식 프로세스에서 sort 명령에 의해 생성된 출력(output)은 터미널로 전송된다. 그리고 자식 프로세스가 종료되면서 신호(signal)을 전송하고, 이것은 자식 프로세스의 종료를 기다리고 있는부모 프로세스에게 전달된다.
자식 프로세스는 종료되면서 자신의 디폴트 파일 디스크립터 0, 1, 그리고 2를 모두 닫는다(close). 자식 프로세스가 종료되고 나면부모 프로세스 또한 종료되면서 자신의 디폴트 파일 디스크립터 0, 1, 그리고 2를 모두 닫는다(close). 그러면 프로세스 실행 중에 추가적으로 사용되었던 모든 파일 디스크립터들은 닫히게 된다.
특히 위의 다이어그램들 중에서 파란색 선들(blue lines)을 잘 보아라. 그것들은 당시 과정에서 데이터의 흐름(the flow of data)을 나타낸다. 위 다이어그램들을 연결하면 다음과 같은 데이터 흐름을 얻는다:
부모 프로세스는 파이프의 쓰기 엔드를 통해 데이터를 작성한다.
자식 프로세스는 파이프의 읽기 엔드를 통해 stdin에서 데이터를 읽어온다.
자식 프로세스는 sort 명령을 처리하고 결과를 터미널로 출력한다.
이 예제를 통해 알 수 있는 것은 파이프에 의해 생성된 파일 디스크립터들(file descriptors)은 필요할 경우 다른 스트림(e.g. stdin)으로 리다이렉트(redirect)될 수 있다는 것이다. 파이프는 프로세스끼리 서로 통신할 수 있는 2개의 파일 디스크립터를 제공하는 편리한 도구이다. 그리고 파이프(pipe)의 파일 디스크립터(file descriptors)는 데이터가 적절하게 원하는 곳으로 흐를 수 있도록 리다이렉트(redirect)될 수 있다.
위의 예제 코드와 다이어그램들이 프로세스가 파이프를 통해 여러 명령들을 처리하는 과정을 이해하는데 도움이 되었길 바란다. 위 예제를 통해 알아야 할 것은 파일 디스크립터가 어떻게(how) 사용되는지를 이해하는 것도 중요하지만 파일 디스크립터가 어느 시점에(when) 사용되지 않으며, 그걸 경우 적절하게 닫혀야한다는 것을 이해하는 것도 중요하다는 사실이다. 파일 디스크립터의 힘은 강력하지만 잘못 사용할 경우 문제를 일으킬 수 있고, 쉽게 까먹고 놓칠 수도 있는 부분이다.
다음 편에서는 이번 리눅스 명령 실행 원리 시리즈의 마지막으로서 I/O 리다이렉션(Redirection)에 알아보도록 하자.
[리눅스] 명령 실행 원리 1 : 파일 디스크립터(file descriptor)와 데이터 흐름(data flow)
1. 파일 디스크립터(File Descriptors)
유닉스(Unix)에서는 기본적으로 입력(input)을 터미널 키보드와 연결시키고 출력(output)을 터미널 디스플레이와 연결시킨다. 유닉스는 키보드와 모니터를 포함하여 컴퓨터의 모든 것을 파일로 모델링하는 것으로 유명하다. 따라서 디스플레이에 데이터를 쓰는 것은 스크린 위에 데이터 디스플레이를 담당하는 어떤 파일에 데이터를 쓰는 것이다. 비슷하게 키보드에서 데이터를 읽어오는 것은 키보드를 나타내는 어떤 파일에서 데이터를 읽어오는 것이다.
데이터는 바이트를 한 곳에서 다른 곳으로 전송하는 스트림(streams)을 통해 흐른다. 3가지의 디폴트 입출력 스트림들(input/output(I/O) streams)이 있는데 바로 표준 입력(Standard Input(STDIN)), 표준 출력(Standard Output(STDOUT)), 그리고 표준 오류(Standard Error(STDERR))이다. 기본적으로 이 스트림들은 각자 특정한 파일 디스크립터(File Descriptor)를 갖고 있다.
각 파일 디스크립터는 어떤 정수(integer) 값인데 그것은 어떤 하나의 오픈 파일(open file)과 연결되어 있다. 그리고 프로세스들은 파일 디스크립터를 이용해 데이터를 처리한다.
그 3가지의 기본 스트림들은 다음과 같은 파일 디스크립터 숫자를 갖고 있다: stdin=0, stdout=1, 그리고 stderr=2. 이 파일 디스크립터들은 어떤 하나의 파일 디스크립터 테이블(File Descriptor Table)에 저장되어 있다. 그리고 각 프로세스는 자신만의 파일 디스크립터 테이블을 갖고 있으며, 프로세스가 생성될 때 기본적으로 0,1 그리고 2가 해당하는 스트림들에게 각각 맵핑된다.
각 스트림은 자신에게 맵핑된 파일 디스크립터에게 보낸 데이터가 어디로 가는지 또는 그 파일 디스크립터로부터 받은 데이터가 어디로부터 오는지 알 지 못한다. 스트림은 자신의 파일 디스크립터를 통해 데이터를 처리할 뿐 실제 데이터 리소스를 직접 처리하는 것이 아니다. 따라서 프로세스는 파일 디스크립터들만 처리하면 되고 실제 그 파일을 처리하지는 않는다. 대신 커널(kernel)이 안전하게 그 파일을 관리한다.
그리고 프로세스는 0,1,2 이외에도 다른 파일 디스크립터를 사용하게 되는데, 새로운 파일 디스크립터가 할당될 때는 가장 낮은 숫자의 아직 사용되지 않은(unopen) 파일 디스크립터가 사용된다. 따라서 0,1,2가 디폴트로 설정된 이후에 다음으로 사용될 파일 디스크립터는 3이다.
2. 데이터 흐름(Data Flow)
이제 데이터 흐름에 대해 좀 더 깊게 얘기할 준비가 되었다. 우리가 터미널에서 어떤 명령을 실행시킬 때는 입력과 출력이 적절하게 처리되어야 한다. 각 명령은 어떤 데이터를 입력으로 받아야 할지 그리고 어떤 데이터를 출력으로 내보내야 할지를 알아야 한다. 데이터 흐름의 입력(stdin을 통해 기본적으로 키보드로부터 들어오는 데이터)과 데이터 흐름의 출력(stdout을 통해 또는 오류가 발생하면 stderr를 통해 기본적으로 터미널에게 전달되는 데이터)을 나타내기 위해 아래와 같은 다이어그램을 사용할 것이다.
위의 그림은 입력 출력 스트림의 기본 설정을 나타낸다. 키보드는 명령을 수행하는 프로그램에게 데이터를 전달하고(명령의 입장에서는 stdin을 통해 입력을 전달받는다.) 그 프로그램은 stdout을 통해 터미널에게 데이터를 출력한다. 이 그림에서 데이터는 왼쪽에서 오른쪽으로 흐르고 이 경우에 입력(in)은 stdin과 연결되고 출력(out)은 stdout과 연결된다. 그리고 각 입력과 출력에 대응되는 파일 옆에는 파일 디스크립터 번호(0, 1)가 쓰여있다.
일반적으로 데이터가 어떤 곳으로 흘러들어가는 것을 입력이라고 하며, 데이터가 어떤 곳으로부터 흘러나가는 것을 출력이라고 한다. 이러한 개념을 머릿속에 염두하고 있으면, 앞으로 보게 될 더욱 복잡한 다이어그램들을 이해하는데 도움이 될 것이다.
한 가지 알아야 할 사실은 터미널로 데이터를 출력할 수 있는 스트림은 기본적으로 2가지 라는 것이다: stdout과 stderr이다. strerr 스트림은 어떤 명령을 실행시킬 때 오류가 있을 경우 사용된다.
예를 들어 다음과 같은 명령은 존재하지 않는 디렉토리(dir_x)의 컨텐츠를 리스트하려고 한다.
foo@bar:~$ ls dir_x
ls: cannot access dir_x: No such file or directory
위의 예제에서 두 번째 줄을 출력하기 위해 사용된 스트림은 사실 stderr이며, stdout이 아니다. 따라서 stderr 또한 기본적으로 터미널에게 출력하기 때문에 우리는 오류 메시지를 터미널에서 볼 수 있다. 대신 만약 그 디렉토리(dir_x)가 존재했었다면, stdout 스트림을 통해 디렉토리의 컨텐츠를 터미널로 출력했을 것이다.
여기에 업데이트된 다이어그램이 있는데, 이것은 데이터 출력을 위한 2가지의 스트림(stdout, stderr)을 보여주고 있다.
위 그림에서 각 출력 스트림과 연결된 파일 디스크립터 번호(1, 2)를 볼 수 있다. 따라서 stderr 스트림도 출력을 위해 사용될 수 있음을 알게되었다. 하지만 앞으로 보일 다이어그램에서는 예제에서 stderr 스트림을 사용하지 않는 한 간결성을 위해서 stderr 스트림은 생략하도록 할 것이다. 하지만 그것이 존재한다는 사실은 항상 염두해두길 바란다.
우리는 이제 명령을 이용하여 데이터 흐름을 알아볼 것이다. 몇몇 명령들은 입력과 출력 모두를 사용한다. 하지만 몇몇은 둘 중 하나만 사용하거나 아예 사용하지 않는 것도 있다. 우리는 다양한 경우를 다룰 것인데, 우선은 여기서 입력(input)의 진정한 의미에 대해서 알아보자. 쉘(shell)의 입장에서 봤을 때는(쉘은 터미널로 전달된 커맨드 라인을 처리한다.), 키보드로 입력되는 모든 것(그 명령(command) 자체를 포함하여)이 입력(input)인 것이다. 하지만 우리는 좀 더 구체적으로 명령을 처리하는 프로세스가 파일들로부터(키보드와 디스플레이를 포함하여) 데이터를 주고받기 위해서 명령들(commands)에게 필요한 입력과 출력에 대해 다룰 것이다.
명령의 옵션 인자들(option arguments)은 커맨드 라인(command line)으로부터 읽히는데 비해서(옵션 인자들은 배열로 전달된다.) 실제 입력(input)은 파일 디스크립터와 연결된 오픈 파일(open file)로부터 읽힌다. 따라서 나는 명령에 대한 입력(input)을 다음과 같이 정의한다: stdin(또는 리펄포즈된(repurposed) 파일 티스크립터)을 이용해 전달된 데이터. 그리고 그 입력이 키보드를 통해서 입력되었는지, I/O 리다이렉션(redirection)을 통해 리다이렉트되었는지, 또는 명령에게 파일 인자(file argument)로 전달되었는지는 상관없다. 나는 어떤 파일 인자(file argument)가 명령에 전달되었을 때, 프로세스가 실질적으로 그 파일의 컨텐츠를 읽거나(read) 변경할(manipulate) 경우(e.g. sort 명령) 그것을 입력(input)으로 생각할 것이다. 하지만 단순히 그 파일을 참조하는 경우(e.g. mv 명령)에는 입력(input)으로 간주하지 않는다.
추가적으로, 커맨드 라인 옵션 인자들은 어떤 유닉스 디자인 선택의 결과인데, 그것은 받은 입력(input)에 의해 실행되는 명령의 행동 변화가 독립적으로 전달될 수 있게 해준다(?)
이제 예제들을 살펴보자. 명령들 중에서 입력은 없지만 출력은 있는 명령의 한 예로 ls 명령을 생각할 수 있으며, 이것은 현재 디렉토리에 있는 모든 파일과 디렉토리를 나열한다.
foo@bar:~$ ls
dir1 file1 file2
이 명령은 다음과 같이 시각화될 수 있다.
만약 어떤 명령이 stdin으로부터 입력을 받지 않는다면, 그 명령으로 전달되는 데이터는 그 명령을 실행하는 프로그램에 의해 무시될 것이다. 왜냐하면 그 명령은 입력 데이터를 처리하도록 만들어지지 않았기 때문이다. 예를 들어, < words.txt ls 를 입력하면 이것은 현재 디렉토리 안의 모든 파일과 디렉토리를 출력하고 stdin으로 리다이렉트된 입력 데이터는 무시할 것이다.
이제 다음으로 볼 명령은 입력은 없지만 출력은 있는 명령의 한 예로 mv 명령을 생각할 수 있으며, 이것은 파일을 이동시키거나 이름을 바꾸는데 사용된다. 내가 그 명령에게 이동시키거나 이름을 바꾸려고 하는 파일 또는 디렉토리의 이름을 정확히 전달하면, stdout 또는 stderr를 통해 출력 데이터는 없다. 다시 한 번 말하면, 전달되는 파일의 컨텐츠가 읽히거나 또는 사용되는 것이 아니기 때문에 전달된 파일은 입력(input)이 아니다. 명령이 성공적으로 이루어졌을 경우 다음과 같은 다이어그램을 그릴 수 있다.
하지만 만약 mv 명령을 잘못 사용할 경우에는 다음과 같이 오류가 발생하여 stderr를 통해 출력될 것이다.
foo@bar:~$ mv
mv: missing file operand
Try 'mv --help' for more information.
이제 더욱 흥미로운 것들을 해보자. 입력과 출력을 모두 사용하는 명령에 대한 예제에서 내가 제일 좋아하는 것은 sort 명령이다. 만약 파일 인자(file argument)와 입력 리다이렉션이 둘 다 없을 경우 터미널은 사용자가 정렬(sort)할 스트링을 입력할 때까지 대기한다. 그리고 사용자가 Ctrl-D를 입력하면(이것은 sort 프로세스의 stdin과 키보드를 연결하는 커뮤니케이션 채널(communication channel의 쓰기 엔드(write end)를 종료한다.)), 그 sort 명령을 실행하는 프로세스는 필요한 스트링이 전부 입력되었다고 생각할 것이다. 그러므로 그 입력된 스트링들은 stdin을 통해 명령을 실행하는 프로세스에게 전달되고, 그 프로세스에 의해 정렬(sort)된 후, stdout을 통해 터미널에게 출력된다. 매우 훌륭하다! 다음과 같은 예제를 보자.
foo@bar:~$ sort
cherry
banana
apple
apple
banana
cherry
위의 3줄의 단어는 사용자가 입력한 것이고 아래의 3줄의 단어는 sort 명령에 의해 정렬된 결과이다.
sort 명령은 또한 사용자에게 직접 스트링을 입력받지 않고 파일 이름을 인자로 받아 그 파일 안의 스트링을 입력으로 사용할 수 있다(e.g. sort words.txt). 이것은 아까 말한 입력(input)의 정의를 만족하는데, 왜냐하면 그것은 파일(file)이면서 sort -r과 같은 옵션 인자(option argument)가 아니기 때문이다. 게다가, sort 명령은 리다이렉션을 통해서도 입력을 전달받을 수 있다.
이제 우리는 stdin으로부터 stdout 또는 stderr로 전달되는 데이터 흐름의 일반적인 개념을 공부했다. 우리는 이제 어떻게 그 입력과 출력의 흐름을 제어하는지 알아볼 것이다. 나는 이를 위해서 2가지 방법을 사용할 것이다. 첫 번째는 파이프(pipe)를 사용하는 것인데, 이것은 한 프로세스의 출력이 다른 프로세스의 입력으로 전달되도록 해준다. 그리고 두 번째로는 I/O 리다이렉션(redirection)을 사용할 것인데, 이것은 키보드나 터미널 대신에 파일들(files)이 데이터의 입력과 출력으로 사용되도록 해준다.